텍스트와 개체 영역을 결합해 확산 모델 확장

마이크로소프트(MS)는 이미지 생성 인공지능(AI)이 출력하는 이미지에 포함된 특정 개체의 위치를 지정할 수 있는 AI 모델 ‘레코(ReCo)’를 공개했다고 마크테크포스트가 25일(현지시간) 보도했다.
이미지 생성 AI는 출력 이미지를 텍스트 프롬프트로 설명하면 사실적인 이미지를 생성한다. 이러한 이미지 생성 AI는 ‘확산 모델’로 알려져 있다. 확산 모델은 방대한 훈련 데이터 세트를 통해 텍스트 프롬프트에서 이미지를 생성하는 방법을 학습한다. 처음부터 이미지를 그리는 것과는 반대로 이미지를 ‘재작성’하도록 훈련된 모델은 순수한 노이즈(noise)로 시작해 이미지를 다듬어 점차적으로 텍스트 프롬프트에 더 가깝게 만든다.
확산 모델이 사실적인 이미지를 생성하지만 사용자가 원하는 이미지를 얻으려면 많은 텍스트 프롬프트를 시도하고 원하는 이미지에 가장 가까운 출력을 선택해야 한다. 시간이 오래 걸리며 원하는 이미지를 생성한다는 보장도 없다.
특히 출력 이미지의 특정 위치에서 원하는 개체를 정확하게 생성하기가 어렵다. 예를 들어 ‘왼쪽 상단 모서리에 있는 도넛’과 같이 특정 위치에 특정 개체를 그리려는 경우 기존 모델은 이를 수행하는 데 어려움을 겪을 수 있다. 또 입력 텍스트 프롬프트가 길고 다소 복잡할 때 기존 모델은 특정 세부 사항을 간과하고 학습 단계에서 배운 사전 정보를 그대로 사용한다.
종합하면 기존 모델은 생성된 이미지 내에서 특정 개체의 위치를 지정하는 영역 제어가 어렵다.
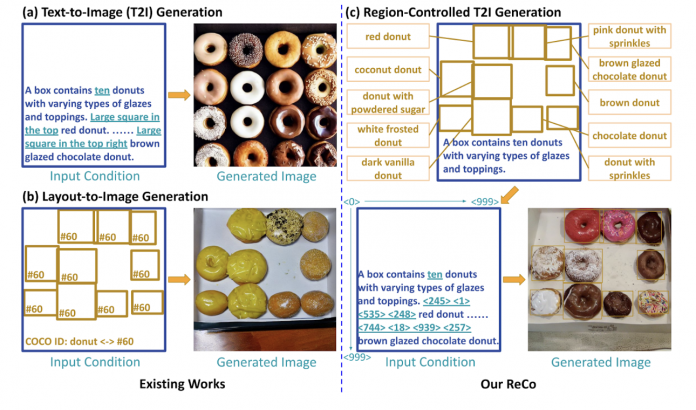
반면 ‘레코’는 기존 확산 모델을 확장해 정밀하게 제어되는 출력 이미지를 생성할 수 있는 영역 제어 이미지 생성 모델이다. 영역 제어 이미지 생성 모델은 레이아웃-이미지(layout-to-image) 문제와 밀접한 관련이 있다. 레코는 레이블이 있는 객체 경계 상자를 입력으로 사용해 원하는 이미지를 생성한다.
레코는 텍스트와 개체 영역을 별도로 모델링하는 대신 레이블에 대한 자유 형식의 텍스트 입력을 이해할 수 있도록 두 입력 조건을 결합해 함께 모델링한다. 이렇게 하면 두 가지 입력 조건인 텍스트와 영역을 매끄럽게 결합할 수 있다.
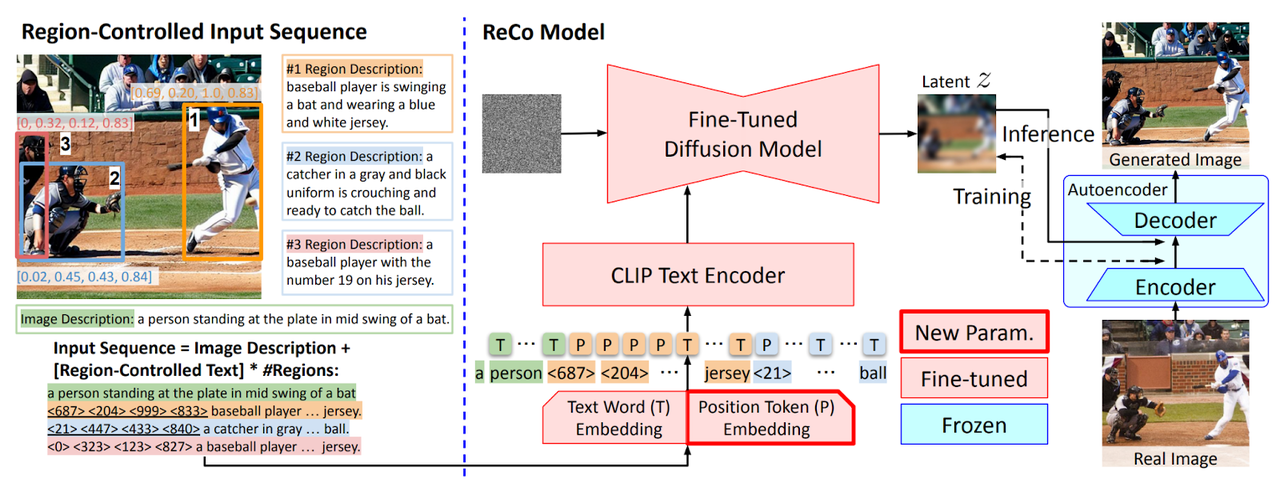
레코는 기존 텍스트-이미지 모델의 확장이다. 이를 통해 선행 학습된 모델이 공간 좌표 입력을 이해할 수 있다. 핵심 아이디어는 공간 위치를 나타내기 위해 추가로 입력 위치 토큰 세트를 도입하는 것이다. 이러한 위치 토큰은 이미지를 동일한 크기의 영역으로 분할해 이미지에 포함된다. 그런 다음 각 토큰을 가장 가까운 영역에 포함할 수 있다.
레코의 위치 토큰은 이미지의 모든 영역에 대한 정확한 설명 방법을 제공해 영역 제어가 가능한 새로운 텍스트 입력 인터페이스를 지원한다.
박찬 위원 cpark@aitimes.com
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com