
Abstract
A century after the first twin and adoption studies of behavior in the 1920s, this review looks back on the journey and celebrates milestones in behavioral genetic research. After a whistle-stop tour of early quantitative genetic research and the parallel journey of molecular genetics, the travelogue focuses on the last fifty years. Just as quantitative genetic discoveries were beginning to slow down in the 1990s, molecular genetics made it possible to assess DNA variation directly. From a rocky start with candidate gene association research, by 2005 the technological advance of DNA microarrays enabled genome-wide association studies, which have successfully identified some of the DNA variants that contribute to the ubiquitous heritability of behavioral traits. The ability to aggregate the effects of thousands of DNA variants in polygenic scores has created a DNA revolution in the behavioral sciences by making it possible to use DNA to predict individual differences in behavior from early in life.
Similar content being viewed by others

Introduction
Although the history of heredity and behavior can be traced back to ancient times (Loehlin 2009), the first human behavioral genetic research was reported in the 1920s, which applied quantitative genetic twin and adoption designs to assess genetic influence on newly developed measures of intelligence. The 1920s also marked the beginning of single-gene research that led to molecular genetics. The goal of this review is to outline 100 years of progress in quantitative genetic and molecular genetic research on behavior, a whistle-stop tour of a few of the major milestones in the journey. The review focuses on human research even though non-human animal research played a major role in the first 50 years (Maxson 2007). It uses intelligence as a focal example because intelligence was the target of much human research, even though a similar story could be told for other areas of behavioral genetics such as psychopathology.
The Two Worlds of Genetics
The most important development during this century of behavioral genetic research has been the synthesis of the two worlds of genetics, quantitative genetics and molecular genetics. Quantitative genetics and molecular genetics both have their origins in the 1860s with Francis Galton (Galton 1865, 1869) and Gregor Mendel (Mendel 1866), respectively. Not much happened until the 1900s when Galton’s insights led to methods to study genetic influence on complex traits and when Mendel’s work was re-discovered. The two worlds clashed as Mendelians looked for 3:1 segregation ratios indicative of single-gene traits, whereas Galtonians assumed that Mendel’s laws of heredity were specific to pea plants because they knew that complex traits are distributed continuously.
Antipathy between the two worlds of genetics followed because of the different goals of Mendelians and Galtonians. Mendelians, the predecessors of molecular geneticists, wanted to understand how genes work, which led to the use of induced mutations and a focus on dichotomous traits that were easily assessed such as physical characteristics rather than behavioral traits. In contrast, Galtonians, whose descendants are quantitative geneticists, used genetics as a tool to understand the etiology of naturally occurring variation in complex traits selected for their intrinsic interest and importance, with behavioral traits, especially intelligence, high on the list. The resolution to the conflict could be seen in Ronald Fisher’s 1918 paper, which showed that Mendelian inheritance is compatible with quantitative traits if the assumption is made that several genes affect a trait (Fisher 1918). Nonetheless, the two worlds of genetics went their own way for most of the century.
The synthesis of the two worlds of genetics began in the 1980s with the technological advances of DNA sequencing, polymerase chain reaction, and DNA microarrays that enabled genome-wide association (GWA) studies of complex traits. In addition to finding DNA variants associated with complex traits, GWA genotypes led to three far-reaching advances in genetic research. First, GWA genotypes were used to estimate directly the classical quantitative genetic parameters of heritability and genetic correlation, which could be called quantitative genomics. Second, the results of GWA studies were used to create polygenic scores that predict individual differences for complex traits. Third, GWA genotypes facilitated new approaches to causal modeling of the interplay between genes and environment. Together, when applied to behavioral traits, these advances could be called behavioral genomics. This synthesis of the two worlds of genetics, the journey from behavioral genetics to behavioral genomics, is the overarching theme of this whistle-stop tour celebrating a century of research in behavioral genetics. (See Fig. 1.) The itinerary begins with milestones in quantitative genetics and then molecular genetics, concluding with behavioral genomics.

Synthesis of the two worlds of genetics: from behavioral genetics to behavioral genomics.
Quantitative Genetics
The first 50 years of quantitative genetic research, from 1920 to 1970, started off well with family studies (Jones 1928; Thorndike 1928), twin studies (Holzinger 1929; Lauterbach 1925; Merriman 1924; Tallman 1928) and adoption studies (Burks 1928; Freeman et al. 1928) using the recently devised IQ test. However, this nascent research was squelched with the emergence of Nazi eugenic policies (McGue 2008). The void was filled with behaviorism (Watson 1930), which led to environmentalism, the ‘blank slate’ view that we are what we learn (Pinker 2003).
Nonetheless, a few studies of IQ appeared in the 1930 and 1940 s, such as the first study of identical twins reared apart (Newman et al. 1937) and the first adoption study that assessed birth parents (Skodak and Skeels 1949). Both indicated substantial genetic influence on IQ, as did a review of all available IQ data (Woodworth 1941).
In 1960, the field-defining book, Behavior Genetics (Fuller and Thompson 1960), was published. It mostly reviewed research on nonhuman animals. In their preface, the authors noted that “we considered omitting human studies completely” (p. vi); even their chapter on cognitive abilities primarily reviewed nonhuman research. An earlier influential review began by saying, “In the writer’s opinion, the genetics of behavior must be worked out on species that can be subjected to controlled breeding. At the present time this precludes human subjects” (Hall 1951).
In 1963, a milestone review was published in Science of 52 family, twin and adoption studies of IQ (Erlenmeyer-Kimling and Jarvik 1963). Although the studies were very small by modern standards and heritability was not calculated, the average results from the different designs suggested substantial heritability. For example, the average MZ and DZ twin correlations were 0.87 and 0.53, respectively, suggesting a heritability of 68%. However, despite being published in Science, the paper was largely ignored; it was cited only 22 times in five years.
The pace of behavioral genetic research picked up in the 1960s, once again primarily research on non-human animals (Lindzey et al. 1971; McClearn 1971), although some twin studies on cognitive abilities were also published (Nichols 1965; Schoenfeldt 1968). However, the first 50 years of quantitative genetic research ended badly with the publication in 1969 of Arthur Jensen’s paper, How Much Can We Boost IQ and Scholastic Achievement? (Jensen 1969). The paper touched on ethnic differences, which made it one of the most controversial papers in the behavioral sciences, with 900 citations in the first five years and more than 6200 citations in total.
1970 was a watershed year marking the second 50 years of behavioral genetic research. It was the year that the Behavior Genetics Association was launched and the first issue of its journal, Behavior Genetics, was published. Another 1970 milestone was the publication of the foundational paper for model-fitting analysis of quantitative genetic designs (Jinks and Fulker 1970).
The 1970s and 1980s yielded most of the major discoveries for quantitative genetics as applied to behavioral traits, discoveries that are listed as landmarks in the following paragraphs. Nonetheless, in the aftermath of Jensen’s 1969 paper, behavioral genetic research, especially on intelligence, was highly controversial (Scarr and Carter-Saltzman 1982). Most notably, Leon Kamin severely criticized the politics as well as science of behavioral genetic research on intelligence in his book, The Science and Politics of I.Q. (Kamin 1974). He concluded that “There exist no data which should lead a prudent man to accept the hypothesis that I.Q. test scores are in any degree heritable” (p. 1). The book was cited more than 2000 times and stoked antipathy towards genetic research. It also impugned the motivation of genetic researchers, saying that they are ‘committed to the view that those on the bottom are genetically inferior victims of their own immutable defects’ (p. 2).
All Traits are Heritable
Despite this hostility, genetic research grew exponentially in the 1970s and created a seismic shift from the prevailing view that behavioral traits like intelligence are not “in any degree heritable”. In 1978, a review of 30 twin studies of intelligence yielded an average heritability estimate of 46% (Nichols 1978). Moreover, the conclusion began to emerge that all traits show substantial heritability. This conclusion, which has been called the first law of behavioral genetics (Turkheimer 2000), was first observed in 1976 in a twin study of cognitive data for 3000 twin pairs, which also included extensive data on personality and interests for 850 twin pairs (Loehlin and Nichols 1976). The authors noted “the curious uniformity of identical-fraternal differences both within and across trait domains” (p. 89). A 2015 meta-analysis of all published twin studies showed that behavioral traits are about 50% heritable on average (Polderman et al. 2015). Demonstrating the ubiquitous importance of genetics was the fundamental accomplishment of behavioral genetics.
No Traits are 100% Heritable
The flip side of the finding of 50% heritability was just as important: no traits are 100% heritable. It is ironic that, after a century of environmentalism, genetic research provided the strongest evidence for the importance of the environment; previous environmental research was confounded because it ignored genetics. Moreover, investigating environmental influences in genetically sensitive designs led to two of the most important discoveries about the environment: nonshared environment and the nature of nurture.
Nonshared Environment
Quantitative genetic research showed that environmental influences work very differently from the way they were assumed to work. A second discovery by Loehlin and Nichols (1976) was that salient environmental influences are not shared by twins growing up in the same family: “Environment carries substantial weight in determining personality – it appears to account for at least half the variance – but that environment is one for which twin pairs are correlated close to zero” (p. 92). This phenomenon has come to be known as nonshared environment (Plomin and Daniels 1987).
Loehlin and Nichols suggested that cognitive abilities are an exception to the rule that environmental influences make children in a family different from, not similar to, one another. Their twin study suggested that about 25% of the variance of cognitive abilities could be attributed to shared environment. A direct test of shared environmental influence is the correlation between adoptive siblings, genetically unrelated children adopted into the same family. Seven small studies of adoptive siblings yielded an average IQ correlation of 0.25, which seemed to precisely confirm the twin estimate (McGue et al. 1993).
However, in 1978, a study of 100 pairs of adoptive siblings reported an IQ correlation of -0.03 (Scarr and Weinberg 1978). This is a good example of the progressive nature of behavioral genetic research (Urbach 1974). Scarr and Weinberg noted that previous studies involved children, whereas theirs was the first study of post-adolescent adoptive siblings aged 16 to 22, and they hypothesized that the effect of shared environmental influence on cognitive development diminishes after adolescence as young adults make their own way in the world. Their hypothesis was confirmed in two additional studies of post-adolescent adoptive siblings that yielded an average IQ correlation of -0.01 (McGue et al. 1993). Evidence that shared environmental influence declines after adolescence to negligible levels for cognitive abilities has also emerged from twin studies (Briley and Tucker-Drob 2013; Haworth et al. 2010). However, one of the biggest mysteries about nonshared environment remains: what are these environmental influences that make children growing up in the same family so different (Plomin 2011)?
The Nature of Nurture
Another milestone was the revelation that environmental measures widely used in the behavioral sciences, such as parenting, social support, and life events, show genetic influence (Plomin and Bergeman 1991), with heritabilities of about 25% on average (Kendler and Baker 2007). This finding emerged in the 1980s as measures of the environment were included in quantitative genetic designs, which also led to the discovery that associations between environmental measures and psychological traits are significantly mediated genetically (Plomin et al. 1985). The nature of nurture is one of the major directions for research in behavioral genomics, as discussed later.
Heritability Increases During Development
Another milestone in the 1970s was the Louisville Twin Study in which mental development of 500 pairs of twins was assessed longitudinally and showed that the heritability of intelligence increases from infancy to adolescence (Wilson 1983). In light of the replication crisis in science (Ritchie 2021), a cause for celebration is that this counterintuitive finding of increasing heritability of intelligence – from about 40% in childhood to more than 60% in adulthood -- has consistently replicated, as seen in cross-sectional (Haworth et al. 2010) and longitudinal (Briley and Tucker-Drob 2013) mega-analyses.
Pleiotropy
In 1977, a landmark paper showed how univariate analysis of variance can be extended to multivariate analysis of covariance in a model-fitting framework (Martin and Eaves 1977). They applied their approach to cognitive abilities and found an average genetic correlation of 0.52, indicating that many genes affect diverse traits, called pleiotropy. Subsequent studies also yielded genetic correlations greater than 0.50 between diverse cognitive abilities (Plomin and Kovas 2005).
Summary
In the 1970s and 1980s, bigger and better studies made most of the major quantitative genetic discoveries, going far beyond merely estimating heritability. But it was not all smooth sailing. Most notably, The Bell Curve resurrected many of the issues that followed Jensen’s 1969 paper (Herrnstein and Murray 1996). Nonetheless, by the 1990s, quantitative genetic research had convinced most scientists of the importance of genetics for behavioral traits, including intelligence (Snyderman and Rothman 1990). One symbol of this change was that the 1992 Centennial Conference of the American Psychological Association chose behavioral genetics as one of two themes that best represented the past, present, and future of psychology (Plomin and McClearn 1993). Then, just as quantitative genetic discoveries began to slow, the synthesis with molecular genetics began, which led to the DNA revolution and behavioral genomics.
Molecular Genetics
During its first 50 years, molecular genetics focused on single-gene disorders. In 1933, a Nobel prize was awarded to Thomas Hunt Morgan for mapping genes responsible for single-gene mutations in fruit flies (Morgan et al. 1923), but human mapping was stymied because only a few single-gene markers such as blood types were available – variants in DNA itself were not available for another fifty years. Research on single-gene effects discovered in pedigree studies only incidentally involved behavioral traits. For example, phenylketonuria, the most common single-gene metabolic disorder, was discovered in 1934 (Folling 1934) and shown to be responsible for 1% of the population institutionalized for severe intellectual disability.
In the 1940s, it became clear that DNA is the mechanism of heredity, culminating in the most famous paper in biology which proposed the double-helix structure of DNA (Watson and Crick 1953). An important milestone for human behavioral genetics was the discovery in 1959 that the most common form of intellectual disability, Down syndrome, was due to a trisomy of chromosome 21 (Lejeune et al. 1959).
In 1961, the genetic code was cracked showing that three-letter sequences of the four-letter alphabet of DNA coded for the 20 amino acids (Crick et al. 1961). Just as with quantitative genetics, the 1970s was a watershed decade that ushered in the second 50 years, the genomics era.
The Genomics Era
The era of genomics began in the 1970s when methods were developed to sequence DNA’s nucleotide bases (Sanger et al. 1977). In 2003, fifty years after the discovery of the double helix structure of DNA, the Human Genome Project identified the sequence of 92% of the three billion nucleotide bases in the human genome (Collins et al. 2003).
In the 1980s, the first common variants in DNA itself were discovered, restriction fragment length polymorphisms (RFLPs) (Botstein et al. 1980). RFLPs enabled linkage mapping for single-gene disorders and were the basis for DNA fingerprinting, which revolutionized forensics (Jeffreys 1987). Polymerase chain reaction (PCR) was also developed which facilitated genotyping by rapidly amplifying DNA fragments (Mullis et al. 1986). In the 1980s, these developments increased the pace of linkage mapping of single-gene disorders, many of which had cognitive consequences, such as phenylketonuria (Woo et al. 1983) and Huntington disease (Gusella et al. 1983). In the 1990s, DNA sequencing revealed thousands of single-nucleotide polymorphisms (SNPs), the most common DNA variant (Collins et al. 1997).
In the 1990s, linkage was also attempted for complex traits that did not show single-gene patterns of transmission, such as reading disability (Cardon et al. 1994), but these were unsuccessful because linkage, which traces chromosomal recombination between disease genes and DNA variants within families, is unable to detect small effect sizes (Plomin et al. 1994). Researchers then pivoted towards allelic association in unrelated individuals, which is much more powerful in detecting DNA variants of small effect size. An early example of association was an allele of the apolipoprotein E gene on chromosome 19 that was found in 40% of individuals with late-onset Alzheimer disease as compared to 15% in controls (Corder et al. 1993).
The downside of allelic association is that an association can only be detected if a DNA variant is itself the functional gene or very close to it. For this reason, and because genotyping each DNA variant was slow and expensive, the 1990s became the decade of candidate gene studies in which thousands of studies reported associations between complex behavioral traits and a few ‘candidate’ genes, typically neurotransmitter genes thought to be involved in behavioral pathways. However, these candidate-gene associations failed to replicate because these studies committed most of the sins responsible for the replication crisis (Ioannidis 2005). For example, when 12 candidate genes reported to be associated with intelligence were tested in three large samples, none replicated (Chabris et al. 2012).
Genome-wide Association
In 1996, an idea emerged that was the opposite of the candidate-gene approach: using thousands of DNA variants to systematically assess associations across the genome in large samples of unrelated individuals (Risch and Merikangas 1996). However, genome-wide association (GWA) seemed a dream because genotyping was slow and expensive.
The problem of genotyping each DNA variant in large samples was solved in the 2000s by the commercial availability of DNA microarrays, called SNP chips, which genotype hundreds of thousands of SNPs for an individual quickly, accurately, and inexpensively. SNP chips paved the way for GWA analyses. In 2007, the first major GWA analysis included 2000 cases for each of seven major disorders and compared SNP allele frequencies for these cases with controls (The Wellcome Trust Case Control Consortium 2007). Replicable associations were found but they were few in number and extremely small in effect size. Hundreds of GWA reports appeared in the next decade with similarly small effect sizes across the behavioral and biological sciences (Visscher et al. 2017), including cognitive traits such as educational attainment (Rietveld et al. 2013) and intelligence in childhood (Benyamin et al. 2014) and adulthood (Davies et al. 2011).
These GWA studies led to the realization that the biggest effect sizes were much smaller than anyone anticipated. For case-control studies, risk ratios were less than 1.1, and for dimensional traits, variance explained was less than 0.001. This meant that huge sample sizes would be needed to detect these miniscule effects, and thousands of these associations would be needed to account for heritability, which is usually greater than 50% for cognitive traits. Ever larger GWA samples scooped up more of these tiny effects. Most recently, a GWA meta-analysis with a sample size of 3 million netted nearly four thousand independent significant associations after correction for multiple testing, but the median effect size of these SNPs accounted for less than 0.0001 of the variance (Okbay et al. 2022).
A century after Fisher’s 1918 paper, the discovery of such extreme polygenicity (Boyle et al. 2017; Visscher et al. 2021) was a turning point in the voyage from behavioral genetics to behavioral genomics. GWA genotypes brought the two worlds of genetics together by making it possible to use GWA genotypes to create three sets of tools to investigate highly polygenic traits: quantitative genomics, polygenic scores, and causal modeling (see Fig. 1). When applied to behavioral traits, these tools constitute the new field of behavioral genomics.
Quantitative Genomics
What good are SNP associations that account for such tiny effects? The molecular genetic goal of tracking effects from genes to brain to behavior is daunting when the effects are so small. However, in contrast to this bottom-up approach from genes to behavior, the top-down perspective of behavioral genetics answered this question by using GWA genotypes to estimate quantitative genetic parameters of heritability and genetic correlations, which could be called quantitative genomics. The journey picked up speed as quantitative genomics led to three new milestones.
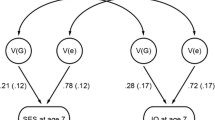
Genome-wide Complex Trait Analysis (GCTA). In 2011, the first new method was devised to estimate heritability and genetic correlations since twin and adoption designs in the early 1900s. GCTA (originally called GREML) uses GWA genotypes for large samples of unrelated individuals to compare overall SNP similarity to phenotypic similarity pair by pair for all pairs of individuals (Yang et al. 2011). The extent to which SNP similarity explains trait similarity is called SNP heritability because it is limited to heritability estimated by the SNPs on the SNP chip. Genetic correlations are estimated by comparing each pair’s SNP similarity to their cross-trait phenotypic similarity.
SNP heritability estimates are about half the heritability estimated by twin studies (Plomin and von Stumm 2018). This ‘missing heritability’ occurs because SNP heritability is limited to the common SNPs genotyped on current SNP chips, which also creates a ceiling for discovery in GWA research. Most SNPs are not common, and rare SNPs appear to be responsible for much of the missing heritability, at least for height (Wainschtein et al. 2022). Importantly, quantitative genomic estimates of genetic correlations are not limited in this way and thus provide estimates of genetic correlations similar to those from twin studies (Trzaskowski et al. 2013).
Linkage Disequilibrium Score (LDSC) Regression. In 2015, a second quantitative genomic method, LDSC, was published which estimates heritability and genetic correlations from GWA summary effect size statistics for each SNP, corrected for linkage disequilibrium between SNPs (Bulik-Sullivan et al. 2015). LDSC estimates of heritability and genetic correlations are similar to GCTA estimates, although GCTA estimates are generally more accurate (Evans et al. 2018; Ni et al. 2018). The advantage of LDSC is that it can be applied to published GWA summary statistics in contrast to GCTA which requires access to GWA data for individuals in the GWA study.
Genomic Structural Equation Modeling (Genomic SEM). In 2019, a third quantitative genomic analysis completed the arc from quantitative genetics to quantitative genomics by combining quantitative genetic structural equation model-fitting, routinely used in twin analyses, to LDSC heritabilities and genetic correlations (Grotzinger et al. 2019). Genomic SEM provides insights into the multivariate genetic architecture of cognitive traits (Grotzinger et al. 2019) and psychopathology (Grotzinger et al. 2022).
The second answer to the question about what to do with SNP associations that have such small effect sizes is the creation of polygenic scores.
Polygenic Scores
A milestone that marks the spot where the DNA revolution began to transform the behavioral sciences is polygenic scores. Rather than using GWA genotypes to estimate SNP heritabilities and genetic correlations, polygenic scores use GWA genotypes to create a single score for each individual that aggregates, across all SNPs on a SNP chip, an individual’s genotype for each SNP (0, 1 or 2) weighted by the SNP’s effect size on the target trait as indicated by GWA summary statistics. In 2001, polygenic scores were introduced in plant and animal breeding (Meuwissen et al. 2001) and later in cognitive abilities (Harlaar et al. 2005) and psychopathology (Purcell et al. 2009). GWA summary statistics needed to create polygenic scores are now publicly available for more than 500 traits, including dozens for psychiatric disorders and other behavioral traits including cognitive traits (PGS Catalog 2022).
The most predictive polygenic scores in the behavioral sciences are for cognitive traits, especially educational attainment and intelligence. Early GWA studies of cognitive traits were underpowered to detect the small effects that we now know are responsible for heritability (Plomin and von Stumm 2018). In 2013, a landmark was a GWA study of educational attainment with a sample size exceeding 100,000 (Rietveld et al. 2013). A polygenic score derived from its GWA summary statistics predicted 2% of the variance of educational attainment in independent samples. The finding that the biggest effects accounted for only 0.0002 of the variance of educational attainment made it clear that much larger samples would be needed to scoop up more of the tiny effects responsible for the twin heritability estimate of about 40%. In the past decade, the predictive power of polygenic scores for educational attainment has increased with increasing sample sizes from 2% (Rietveld et al. 2013) to 5% (Okbay et al. 2016) to 10% (Lee et al. 2018) to 14% in a GWA study with a sample size of three million (Okbay et al. 2022). The current polygenic score for intelligence, derived from a GWA study with a sample of 280,000, predicted 4% of the variance (Savage et al. 2018), but, together, the polygenic scores for educational attainment and intelligence predicted 10% of the variance of intelligence test scores (Allegrini et al. 2019).
The next milestone will be to narrow the gap between heritability explained by polygenic scores and SNP heritability. A more daunting challenge will be to break through the ceiling of SNP heritability to reach the heritability estimated by twin studies. Reaching both of these destinations will be facilitated by even larger GWA studies and whole-genome sequencing (Wainschtein et al. 2022).
Polygenic scores are unique predictors because inherited DNA variations do not change systematically during life – there is no backward causation in the sense that nothing in the brain, behavior or environment changes inherited differences in DNA sequence. For this reason, polygenic scores can predict behavioral traits from early in life without knowing anything about the intervening pathways between genes, brain, and behavior.
Polygenic scores have brought behavioral genetics to the forefront of research in many areas of the life sciences because polygenic scores can be created in any sample of unrelated individuals for whom GWA genotype data are available. No special samples of twins or adoptees are needed, nor is it necessary to assess behavioral traits in order to use polygenic scores to predict them.
Although the implications and applications of polygenic scores derive from its power to predict behavioral traits without regard to explanation (Plomin and von Stumm 2022), another milestone on the road to behavioral genomics has been the leverage provided by GWA genotypes for causal modeling.
Causal Modeling
A final milestone on the journey from behavioral genetics to behavioral genomics is a suite of new approaches that use GWA genotypes in causal models that attempt to dissect sources of genetic influence on behavioral traits (Pingault et al. 2018). Although traditional quantitative genetic models are causal models, GWA genotypes have enhanced causal modeling in research on assortative mating (Border et al. 2021; Yengo et al. 2018), population stratification (Abdellaoui et al. 2022; Lawson et al. 2020), and Mendelian randomization (Richmond and Davey Smith 2022).
An explosion of research on genotype-environment correlation was ignited by a 2018 paper in Science on the topic of the nature of nurture (Kong et al. 2018). The study included both parent and offspring GWA genotypes and showed that a polygenic score computed from non-transmitted alleles from parent to offspring influenced offspring educational attainment; these indirect effects were dubbed genetic nurture. GCTA has also been used to investigate genotype-environment correlation (Eilertsen et al. 2021). Although a great strength of behavioral genomics is its ability to investigate genetic influence in samples of unrelated individuals, combining GWA genotypes with traditional quantitative genetic designs has also enriched causal modeling (McAdams et al. 2022), for example, by comparing results within and between families (Brumpton et al. 2020; Howe et al. 2022).
Conclusion
This whistle-stop tour has highlighted some of the milestones in a century of research in behavioral genetics. The progress is unmatched in the behavioral sciences and its discoveries have been transformative. The most exciting development is the synthesis of quantitative genetics and molecular genetics into behavioral genomics. The energy from this fusion will propel the field far into the future.
References
Abdellaoui A, Dolan CV, Verweij KJH, Nivard MG (2022) Gene–environment correlations across geographic regions affect genome-wide association studies. Nat Genet 54:1345–1354. https://doi.org/10.1038/s41588-022-01158-0
Allegrini AG, Selzam S, Rimfeld K et al (2019) Genomic prediction of cognitive traits in childhood and adolescence. Mol Psychiatry 24:819–827. https://doi.org/10.1038/s41380-019-0394-4
Benyamin B, Pourcain Bs, Davis OS et al (2014) Childhood intelligence is heritable, highly polygenic and associated with FNBP1L. Mol Psychiatry 19:253–258. https://doi.org/10.1038/mp.2012.184
Border R, O’Rourke S, de Candia T et al (2021) Assortative mating biases marker-based heritability estimators. Nat Genet 13:660. https://doi.org/10.1038/s41467-022-28294-9
Botstein D, White RL, Skolnick M, Davis RW (1980) Construction of a genetic linkage map in man using restriction fragment length polymorphisms. Am J Hum Genet 32:314–331
Boyle EA, Li YI, Pritchard JK (2017) An expanded view of complex traits: from polygenic to omnigenic. Cell 169:1177–1186. https://doi.org/10.1016/j.cell.2017.05.038
Briley DA, Tucker-Drob EM (2013) Explaining the increasing heritability of cognitive ability across development: a meta-analysis of longitudinal twin and adoption studies. Psychol Sci 24:1704–1713. https://doi.org/10.1177/0956797613478618
Brumpton B, Sanderson E, Heilbron K et al (2020) Avoiding dynastic, assortative mating, and population stratification biases in Mendelian randomization through within-family analyses. Nat Commun 11:3519. https://doi.org/10.1038/s41467-020-17117-4
Bulik-Sullivan B, ReproGen C, Psychiatric Genomics Consortium et al (2015) An atlas of genetic correlations across human diseases and traits. Nat Genet 47:1236–1241. https://doi.org/10.1038/ng.3406
Burks BS (1928) The relative influence of nature and nurture upon mental development; a comparative study of foster parent-foster child resemblance and true parent-true child resemblance. Teachers Coll Record 29:219–316. https://doi.org/10.1177/016146812802900917
Cardon LR, Smith SD, Fulker DW et al (1994) Quantitative trait locus for reading disability on chromosome 6. Science 266:276–279. https://doi.org/10.1126/science.7939663
Chabris CF, Hebert BM, Benjamin DJ et al (2012) Most reported genetic associations with general intelligence are probably false positives. Psychol Sci 23:1314–1323. https://doi.org/10.1177/0956797611435528
Collins FS, Green ED, Guttmacher AE, Guyer MS (2003) A vision for the future of genomics research. Nature 422:835–847. https://doi.org/10.1038/nature01626
Collins FS, Guyer MS, Chakravarti A (1997) Variations on a theme: cataloging human dna sequence variation. Science 278:1580–1581. https://doi.org/10.1126/science.278.5343.1580
Corder EH, Saunders AM, Strittmatter WJ et al (1993) Gene dose of apolipoprotein e type 4 allele and the risk of alzheimer’s disease in late onset families. Science 261:921–923. https://doi.org/10.1126/science.8346443
Crick FHC, Barnett L, Brenner S, Watts-Tobin RJ (1961) General nature of the genetic code for proteins. Nature 192:1227–1232. https://doi.org/10.1038/1921227a0
Davies G, Tenesa A, Payton A et al (2011) Genome-wide association studies establish that human intelligence is highly heritable and polygenic. Mol Psychiatry 16:996–1005. https://doi.org/10.1038/mp.2011.85
Eilertsen EM, Jami ES, McAdams TA et al (2021) Direct and indirect effects of maternal, paternal, and offspring genotypes: Trio-GCTA. Behav Genet 51:154–161. https://doi.org/10.1007/s10519-020-10036-6
Erlenmeyer-Kimling L, Jarvik LF (1963) Genetics and intelligence: a review. Science 142:1477–1479. https://doi.org/10.1126/science.142.3598.1477
Evans LM, Tahmasbi R, Vrieze SI et al (2018) Comparison of methods that use whole genome data to estimate the heritability and genetic architecture of complex traits. Nat Genet 50:737–745. https://doi.org/10.1038/s41588-018-0108-x
Fisher RA (1918) The correlation between relatives on the supposition of mendelian inheritance. Trans R Soc Edinb 52:399–433. https://doi.org/10.1017/S0080456800012163
Folling A (1934) Excretion of phenylpyruvic acid in urine as a metabolicnomaly in connection with imbecility.Nord Med Tidskr 8:1054-1059
Freeman FN, Holzinger KJ, Mithell BC (1928) The influence of environment on the intelligence, school achievement, and conduct of foster children. Yearbook of the National Society for the Study of Education 1:102–217
Fuller JL, Thompson WR (1960) Behavior genetics. Wiley, New York
Galton F (1865) Hereditary talent and character. Macmillan’s Magazine 12:157–166
Galton F (1869) Hereditary genius: an inquiry into its laws and consequences. Collins, London
Grotzinger AD, Mallard TT, Akingbuwa WA et al (2022) Genetic architecture of 11 major psychiatric disorders at biobehavioral, functional genomic and molecular genetic levels of analysis. Nat Genet 54:548–559. https://doi.org/10.1038/s41588-022-01057-4
Grotzinger AD, Rhemtulla M, de Vlaming R et al (2019) Genomic structural equation modelling provides insights into the multivariate genetic architecture of complex traits. Nat Hum Behav 3:513–525. https://doi.org/10.1038/s41562-019-0566-x
Gusella JF, Wexler NS, Conneally PM et al (1983) A polymorphic DNA marker genetically linked to Huntington’s disease. Nature 306:234–238. https://doi.org/10.1038/306234a0
Hall CS (1951) The genetics of behavior. In: Stevens SS (ed) Handbook of experimental psychology. Wiley, New York, pp 304–329
Harlaar N, Butcher LM, Meaburn E et al (2005) A behavioural genomic analysis of DNA markers associated with general cognitive ability in 7-year-olds. J Child Psychol & Psychiat 46:1097–1107. https://doi.org/10.1111/j.1469-7610.2005.01515.x
Haworth CMA, Wright MJ, Luciano M et al (2010) The heritability of general cognitive ability increases linearly from childhood to young adulthood. Mol Psychiatry 15:1112–1120. https://doi.org/10.1038/mp.2009.55
Herrnstein RJ, Murray CA (1996) The bell curve: intelligence and class structure in American life, 1st Free Press pbk. ed. Simon & Schuster, New York
Holzinger KJ (1929) The relative effect of nature and nurture influences on twin differences. J Educ Psychol 20:241–248. https://doi.org/10.1037/h0072484
Howe LJ, Nivard MG, Morris TT et al (2022) Within-sibship genome-wide association analyses decrease bias in estimates of direct genetic effects. Nat Genet 54:581–592. https://doi.org/10.1038/s41588-022-01062-7
Ioannidis JPA (2005) Why most published research findings are false. PLoS Med 2:e124. https://doi.org/10.1371/journal.pmed.0020124
Jeffreys AJ (1987) Highly variable minisatellites and DNA fingerprints. Biochem Soc Trans 15:309–317. https://doi.org/10.1042/bst0150309
Jensen A (1969) How much can we boost IQ and scholastic achievement? Harv Educational Rev 39:1–123. https://doi.org/10.17763/haer.39.1.l3u15956627424k7
Jinks JL, Fulker DW (1970) Comparison of the biometrical genetical, MAVA, and classical approaches to the analysis of the human behavior. Psychol Bull 73:311–349. https://doi.org/10.1037/h0029135
Jones HE (1928) A first study of parent-child resemblance in intelligence. Yearbook of the National Society for the Study of Education Part 1:61–72
Kamin LJ (1974) The science and politics of I.Q. Routledge, New York, NY
Kendler KS, Baker JH (2007) Genetic influences on measures of the environment: a systematic review. Psychol Med 37:615–626. https://doi.org/10.1017/S0033291706009524
Kong A, Thorleifsson G, Frigge ML et al (2018) The nature of nurture: Effects of parental genotypes. Science 359:424–428. https://doi.org/10.1126/science.aan6877
Lauterbach CE (1925) Studies in twin resemblance. Genetics 10:525–568. https://doi.org/10.1093/genetics/10.6.525
Lawson DJ, Davies NM, Haworth S et al (2020) Is population structure in the genetic biobank era irrelevant, a challenge, or an opportunity? Hum Genet 139:23–41. https://doi.org/10.1007/s00439-019-02014-8
Lee JJ, Wedow R, Okbay A et al (2018) Gene discovery and polygenic prediction from a genome-wide association study of educational attainment in 1.1 million individuals. Nat Genet 50:1112–1121. https://doi.org/10.1038/s41588-018-0147-3
Lejeune J, Gautier M, Turpin R (1959) [Study of somatic chromosomes from 9 mongoloid children]. C R Hebd Seances Acad Sci 248:1721–1722
Lindzey G, Loehlin J, Manosevitz M, Thiessen D (1971) Behavioral genetics. Annu Rev Psychol 22:39–94. https://doi.org/10.1146/annurev.ps.22.020171.000351
Loehlin JC (2009) History of behavior genetics. In: Kim Y-K (ed) Handbook of behavior genetics. Springer New York, New York, NY, pp 3–11
Loehlin JC, Nichols RC (1976) Heredity, environment, and personality: a study of 850 sets of twins. University of Texas Press, Austin, Texas
Martin NG, Eaves LJ (1977) The genetical analysis of covariance structure. Heredity 38:79–95. https://doi.org/10.1038/hdy.1977.9
Maxson SC (2007) A history of behavior genetics. In: Jones BC, Mormee P (eds) Neurobehavioral genetics: methods and applications, 2nd edn. CRC Press, New York, pp 1–16
McAdams TA, Cheesman R, Ahmadzadeh YI (2022) Annual Research Review: towards a deeper understanding of nature and nurture: combining family-based quasi‐experimental methods with genomic data. Child Psychol Psychiatry jcpp 13720. https://doi.org/10.1111/jcpp.13720
McClearn GE (1971) Behavioral genetics. Syst Res 16:64–81. https://doi.org/10.1002/bs.3830160106
McGue M (2008) The end of behavioral genetics? Acta Physiol Sinica 40:1073–1087. https://doi.org/10.3724/sp.j.1041.2008.01073
McGue M, Bouchard TJ, Iacono WG, Lykken (1993) Behavioral genetics of cognitive ability: a life-span perspective. In: Plomin R, McClearn GE, McGuffin P (eds) Nature, nurture and psychology. American Psychological Association, Washington, DC, pp 59–76
Mendel G (1866) Versuche ueber Pflanzenhybriden. Verhandllungen des Naturforschhunden Vereines in Bruenn 4:3–47
Merriman C (1924) The intellectual resemblance of twins. Psychol Monogr 33:i–57. https://doi.org/10.1037/h0093212
Meuwissen THE, Hayes BJ, Goddard ME (2001) Prediction of total genetic value using genome-wide dense marker maps. Genetics 157:1819–1829. https://doi.org/10.1093/genetics/157.4.1819
Morgan TH, Sturtevant AH, Muller HJ, Bridges CB (1923) The mechanism of Mendelian heredity. H. Holt and Company
Mullis K, Faloona F, Scharf S et al (1986) Specific enzymatic amplification of DNA in vitro: the polymerase chain reaction. Cold Spring Harb Symp Quant Biol 51:263–273. https://doi.org/10.1101/SQB.1986.051.01.032
Newman HH, Freeman FN, Holzinger KJ (1937) Twins: a study of heredity and environment. University of Chicago Press
Ni G, Moser G, Wray NR et al (2018) Estimation of genetic correlation via linkage disequilibrium score regression and genomic restricted maximum likelihood. Am J Hum Genet 102:1185–1194. https://doi.org/10.1016/j.ajhg.2018.03.021
Nichols RC (1965) The National Merit Twin Study. In: Vandenberg SG (ed) Methods and goals of human behavior genetics. Academic Press, New York, pp 231–243
Nichols RC (1978) Twin studies of ability, personality, and interests. Homo 29:158–173
Okbay A, Beauchamp JP, Fontana MA et al (2016) Genome-wide association study identifies 74 loci associated with educational attainment. Nature 533:539–542. https://doi.org/10.1038/nature17671
Okbay A, Wu Y, Wang N et al (2022) Polygenic prediction of educational attainment within and between families from genome-wide association analyses in 3 million individuals. Nat Genet 54:437–449. https://doi.org/10.1038/s41588-022-01016-z
PGS Catalog (2022) PGS Catalog. http://www.pgscatalog.org/
Pingault J-B, O’Reilly PF, Schoeler T et al (2018) Using genetic data to strengthen causal inference in observational research. Nat Rev Genet 19:566–580. https://doi.org/10.1038/s41576-018-0020-3
Pinker S (2003) The blank slate: the modern denial of human nature. Penguin, London
Plomin R (2011) Commentary: why are children in the same family so different? Non-shared environment three decades later. Int J Epidemiol 40:582–592. https://doi.org/10.1093/ije/dyq144
Plomin R, Bergeman CS (1991) The nature of nurture: genetic influence on “environmental” measures. Behav Brain Sci 14:373–386. https://doi.org/10.1017/S0140525X00070278
Plomin R, Daniels D (1987) Why are children in the same family so different from one another? Behav Brain Sci 10:1–16. https://doi.org/10.1017/S0140525X00055941
Plomin R, Kovas Y (2005) Generalist genes and learning disabilities. Psychol Bull 131:592–617. https://doi.org/10.1037/0033-2909.131.4.592
Plomin R, Loehlin JC, DeFries JC (1985) Genetic and environmental components of “environmental” influences. Dev Psychol 21:391–402. https://doi.org/10.1037/0012-1649.21.3.391
Plomin R, McClearn GE (eds) (1993) Nature, nurture, & psychology. American Psychological Association, Washington, DC
Plomin R, Owen M, McGuffin P (1994) The genetic basis of complex human behaviors. Science 264:1733–1739. https://doi.org/10.1126/science.8209254
Plomin R, von Stumm S (2018) The new genetics of intelligence. Nat Rev Genet 19:148–159. https://doi.org/10.1038/nrg.2017.104
Plomin R, von Stumm S (2022) Polygenic scores: prediction versus explanation. Mol Psychiatry 27:49–52. https://doi.org/10.1038/s41380-021-01348-y
Polderman TJC, Benyamin B, de Leeuw CA et al (2015) Meta-analysis of the heritability of human traits based on fifty years of twin studies. Nat Genet 47:702–709. https://doi.org/10.1038/ng.3285
Purcell SM, Wray NR, Stone JL et al (2009) Common polygenic variation contributes to risk of schizophrenia and bipolar disorder. Nature 460:748–752. https://doi.org/10.1038/nature08185
Richmond RC, Davey Smith G (2022) Mendelian randomization: concepts and scope. Cold Spring Harb Perspect Med 12:a040501. https://doi.org/10.1101/cshperspect.a040501
Rietveld CA, Medland SE, Derringer J et al (2013) GWAS of 126,559 individuals identifies genetic variants associated with educational attainment. Science 340:1467–1471. https://doi.org/10.1126/science.1235488
Risch N, Merikangas K (1996) The future of genetic studies of complex human diseases. Science 273:1516–1517. https://doi.org/10.1126/science.273.5281.1516
Ritchie S (2021) Science fictions: exposing fraud, bias, negligence and hype in science. Vintage, London
Sanger F, Nicklen S, Coulson AR (1977) DNA sequencing with chain-terminating inhibitors. Proc Natl Acad Sci USA 74:5463–5467. https://doi.org/10.1073/pnas.74.12.5463
Savage JE, Jansen PR, Stringer S et al (2018) Genome-wide association meta-analysis in 269,867 individuals identifies new genetic and functional links to intelligence. Nat Genet 50:912–919. https://doi.org/10.1038/s41588-018-0152-6
Scarr S, Carter-Saltzman L (1982) Genetics and intelligence. In: Sternberg RJ (ed) Handbook of human intelligence. Cambridge University Press, Cambridge, pp 792–895
Scarr S, Weinberg RA (1978) The influence of “family background” on intellectual attainment. Am Sociol Rev 43:674. https://doi.org/10.2307/2094543
Schoenfeldt LF (1968) The hereditary components of the Project TALENT two-day test battery. Meas Evaluation Guidance 1:130–140. https://doi.org/10.1080/00256307.1968.12022379
Skodak M, Skeels HM (1949) A final follow-up study of one hundred adopted children. The Pedagogical Seminary and Journal of Genetic Psychology 75:85–125. https://doi.org/10.1080/08856559.1949.10533511
Snyderman M, Rothman S (1990) The IQ controversy, the media and public policy. Transaction, New Brunswick, NJ
Tallman GG (1928) A comparative study of identical and non-identical twins with respect to intelligence resemblances. Teachers Coll Record 29:83–86. https://doi.org/10.1177/016146812802900912
The Wellcome Trust Case Control Consortium (2007) Genome-wide association study of 14,000 cases of seven common diseases and 3,000 shared controls. Nature 447:661–678. https://doi.org/10.1038/nature05911
Thorndike EL (1928) The resemblance of siblings in intelligence. Teachers Coll Record 29:41–53. https://doi.org/10.1177/016146812802900904
Trzaskowski M, Davis OSP, DeFries JC et al (2013) DNA evidence for strong genome-wide pleiotropy of cognitive and learning abilities. Behav Genet 43:267–273. https://doi.org/10.1007/s10519-013-9594-x
Turkheimer E (2000) Three laws of behavior genetics and what they mean. Curr Dir Psychol Sci 9:160–164. https://doi.org/10.1111/1467-8721.00084
Urbach P (1974) Progress and degeneration in the “IQ debate” I and II. Br J Philosophical Sci 25:99–135
Visscher PM, Wray NR, Zhang Q et al (2017) 10 years of GWAS discovery: biology, function, and translation. Am J Hum Genet 101:5–22. https://doi.org/10.1016/j.ajhg.2017.06.005
Visscher PM, Yengo L, Cox NJ, Wray NR (2021) Discovery and implications of polygenicity of common diseases. Science 373:1468–1473. https://doi.org/10.1126/science.abi8206
Wainschtein P, Jain D, Zheng Z et al (2022) Assessing the contribution of rare variants to complex trait heritability from whole-genome sequence data. Nat Genet 54:263–273. https://doi.org/10.1038/s41588-021-00997-7
Watson JB (1930) Behaviorism, revised. University of Chicago Press, Chicago
Watson JD, Crick FHC (1953) Genetical implications of the structure of deoxyribonucleic acid. Nature 171:964–967. https://doi.org/10.1038/171964b0
Wilson RS (1983) The Louisville Twin Study: developmental synchronies in behavior. Child Dev 54:298. https://doi.org/10.2307/1129693
Woo SLC, Lidsky AS, Güttler F et al (1983) Cloned human phenylalanine hydroxylase gene allows prenatal diagnosis and carrier detection of classical phenylketonuria. Nature 306:151–155. https://doi.org/10.1038/306151a0
Woodworth RS (1941) Heredity and environment: a critical survey of recently published material on twins and foster children. Social Science Research Council, New York
Yang J, Manolio TA, Pasquale LR et al (2011) Genome partitioning of genetic variation for complex traits using common SNPs. Nat Genet 43:519–525. https://doi.org/10.1038/ng.823
Yengo L, Robinson MR, Keller MC et al (2018) Imprint of assortative mating on the human genome. Nat Hum Behav 2:948–954. https://doi.org/10.1038/s41562-018-0476-3
Acknowledgements
This work was supported in part by the UK Medical Research Council (MR/V012878/1 and previously MR/M021475/1).
Author information
Authors and Affiliations
Contributions
The author wrote, reviewed, and submitted the manuscript.
Corresponding author
Ethics declarations
Conflict of Interest
The author has no relevant financial or non-financial interests to disclose.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This review was based on a talk given at the 52nd Behavior Genetics Association Annual Meeting, Los Angeles, California, June 25, 2022.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Plomin, R. Celebrating a Century of Research in Behavioral Genetics. Behav Genet 53, 75–84 (2023). https://doi.org/10.1007/s10519-023-10132-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10519-023-10132-3